
Table of Contents
- Overview
- Kubernetes Architecture
- Designing Your Kubernetes Architecture
- Preparing Ubuntu OS for Kubernetes
- Installing Required Softwares
- Creating the Kubernetes Cluster
- Summary
Overview
In the previous posts, I covered about why I chose Ubuntu over Raspberry Pi OS for Kubernetes. I also covered PXE booting Ubuntu Server 20.04 on Raspberry Pi 4. In this post, I am going to cover how to install Kubernetes step by step on Ubuntu with RPi 4.
Up to this moment, there are so many deployments and services that I had deployed and configured for my Kubernetes environment. For example, I am using HAProxy as my load balancers in front of my K8s cluster. I have Nginx as the ingress controller and NFS as the dynamic storage. However, I will not cover these in this post, but I promise to cover them in the coming posts. So please stay tuned.
Kubernetes Architecture
There are many components in Kubernetes architecture. You will also discover there are many options from different vendors for these components.
It is not my intention to discuss detail about the architecture here. I do not think I want to go there. It can become very complex. However, I think it is still my responsibility to give a high level view of this architecture from the perspective of my RPI4 deployment. I believe this could make the whole thing a lot easier for you to follow.
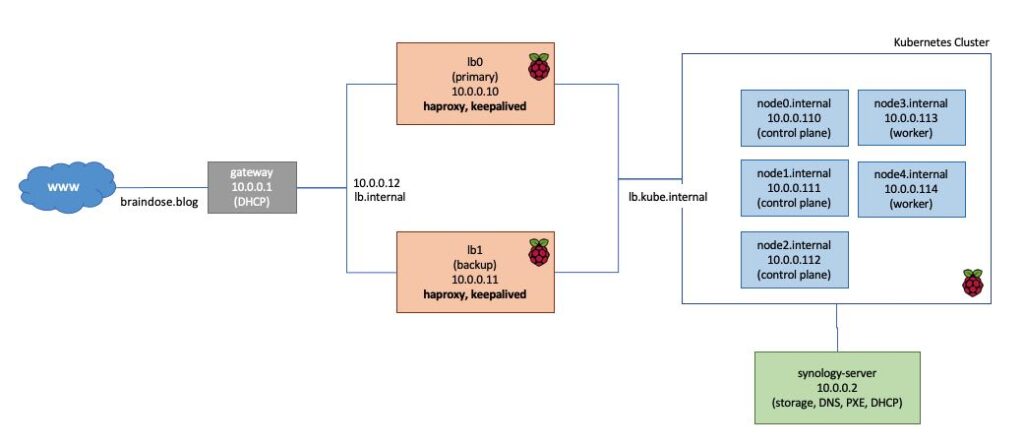
The RPI4s that are keeping the Kubernetes components running is called nodes. We have control plane and worker nodes here in the diagram above. In the past we used to call control plane as master node.
Control planes are reserved to run services that provide management and controller services for the Kubernetes cluster. This includes services such as API to interacts with the management services, services to monitor and scales the containers (or nodes) and etc. It also running data services keep a list of what resources or services are currently running in the cluster.
Your typical applications such as the WordPress that is hosting this blog are to be deployed into the worker nodes.
We typical runs these services and applications as containers on these Kubernetes nodes. The intention is to provide an agile, highly available and scalable applications environment. This is one of the reasons why you need to have more than one worker nodes to ensure that your applications can be scaled to another node if one of the nodes is having issue.
The same reason for having more than one control planes. However, we need at least 3 control planes for high availability because of the data services provided by the control planes.
There are reasons to have discrete control planes and worker nodes. One obvious reason is we do not wish the typical intense applications activities causing resources competitions if both management services and applications services run in the same nodes.
We want to make sure management services are always available. It’s like the brain of the cluster. Your applications and services are considered useless without these management services.
You should notice that my RPI4 cluster is with 3 control planes and 2 worker nodes. Well, I treats the cluster as my production environment. Cheers!
However, you have the choices to run all these services and applications in one single node or 3 nodes (K3s). Usually we settled for one node for non-production. 3 nodes or K3s is the recommended deployment architecture for IoT edge computing which requires lightweight cluster.
Ok, too long. I need to stop here. I hope you have gotten the concept now.
If this is not satisfying your appetite, you can always visit Kubernetes architecture to learn more.
Designing Your Kubernetes Architecture
Before proceeding to install Kubernetes, it is best to think ahead what is the architecture for your Kubernetes cluster including the load balancers, storage, network and etc.
The following table is not an exhausted list but I am using them as a quick start.
| Name | Host Name / Domain Name | IP address | Purpose |
|---|---|---|---|
| Gateway | none | 10.0.0.1 | Gateway, home router :-), DHCP |
| Load balancer #1 | lb0 | 10.0.0.10 | load balancer 1 |
| Load balancer #2 | lb1 | 10.0.0.11 | load balancer 2 |
| Keepalived | lb.internal, lb.kube.internal | 10.0.0.12 | HA for load balancers |
| Synology | synology-server | 10.0.0.2 | storage server, DHCP, TFTP, DNS |
| control plane #1 | node0.internal | 10.0.0.110 | Kubernetes control plane |
| control plane #2 | node1.internal | 10.0.0.111 | Kubernetes control plane |
| control plane #3 | node2.internal | 10.0.0.112 | Kubernetes control plane |
| worker node #1 | node3.internal | 10.0.0.113 | Kubernetes worker node |
| worker node #2 | node4.internal | 10.0.0.114 | Kubernetes worker node |
You also need to consider what is the domain name suffix that you should be using for your Kubernetes services for those that you need to expose externally. In my environment, I am using *.kube.internal as my domain suffix. Of course, this should not stop you from using other domain names.
As a start, I am going to use "lb.kube.internal" as the domain name to point to the external HAProxy load balancer, in front of my control planes. If you are running one control plane, you may not need this.
But it is always a good practice to start with a domain name. This will allows you to easily add more control planes in the future without the need to re-install the whole cluster again (compared to hardcoded). You have the flexibility to change the IP in the future without causing network issue to the cluster.
I have configured the “lb.kube.internal” domain name at DNS server to point to 10.0.0.12 which is the virtual IP address for lb0 and lb1. I have configured the HAProxy to load balance requests to the control plane backends. This domain name will be used during initialising the Kubernetes cluster later.
Preparing Ubuntu OS for Kubernetes
This is assuming you have PXE booting the Ubuntu on RPI4 as per covered in the Part 2. You can apply the same installation steps if you are running Ubuntu on SD Card, which you probably just need to tweak some parts of the steps outlined in this post.
This section covers the pre-requisitions required to install and configure Kubernetes cluster.
Enable CGroup on Ubuntu OS
Remember we have to modify the “cmdline.txt” to configure the PXE boot earlier. Now we need to change this file again to enable CGroup. Kubernetes requires CGroup to provide proper resource limits control and management. You can refer to this site for a better explanation of CGroup.
With your Ubuntu shutdown, ssh into your storage server or using the storage server UI to append the following line in your “cmdline.txt” to enable CGroup.
cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1Configure Fixed IP Address
It is best to configure fixed IP address for each of the Kubernetes node.
I have my Synology DHCP server enabled because I needs the TFTP server enabled. This causes a minor situation where my RPi 4 nodes are automatically assigned with dynamic IP addresses by the DHCP service.
On top of that, I have been using my home router as my default DHCP server from the beginning since the internet exists. I am not going to change my current network architecture because I have tones of other devices, phones, laptops and PCs that are relying on the router. So this router also has been assigning dynamic IPs to my RPi4 nodes.
Having multiple IPs assigned on RPi 4 nodes is not an issue as long as you make sure the hostnames used by Kubernetes nodes are resolved to the correct IP for the nodes.
I prefer a clean approach with one IP per RPi node. I resolved the situation by assigning the same IP to the same network MAC address for each of the node in both the home router and the Synology DHCP server.
All home routers allow you to do that by going into DHCP->Address Reservation (on TP-Link), or something similar. You can do the same at Synology by going to DHCP Server->Network Interface->Edit->DHCP Clients.
To configure the Ubuntu fixed IP address, you need to change the “/etc/netplan/50-cloud-init.yaml” file with the following content after you have booted the Ubuntu.
Note: You can make the changes without booting Ubuntu by doing this at the storage server.
network:
ethernets:
eth0:
addresses: [<your fixed IP address>/24]
gateway4: <your gateway/router IP address>
nameservers:
# command delisted for multiple DNS servers, e.g. [10.0.0.2,10.0.0.3]
addresses: [<your nameserver/DNS server IP address>]
dhcp4: no
optional: no
version: 2The “50-cloud-init.yaml” file is always updated by Ubuntu cloud-init every time the OS is rebooted. The changes you have made will be overwritten because they are not persisted. You need to create a file named “/etc/cloud/cloud.cfg.d/99-disable-network-config.cfg” to disable the auto configuration by cloud-init. The following is the file content.
network: {config: disabled}Update the Ubuntu OS Nameserver
To make sure that all the RPi 4 nodes hostname and any external domain names are resolvable, you need to configure a nameserver that you are going to use internally in your local network.
Run the “system-resolve” command to set the DNS server or nameserver for Ubuntu. Make sure to specify the correct network card interface via the "-i” parameter.
sudo systemd-resolve --set-dns=<nameserver ip> -i=eth0
# Make sure can resolve hostname and load balancer
dig node0.internal +shortIn the above example, I have configured “node0.internal” as “A” record in my DNS server to point to the current node that I am configuring. I perform a “dig” command to verify that the domain name / node name is resolvable to the node’s fixed IP address.
Note: You must be puzzled why we need to run the “systems-resolve” command to configure the nameserver twice. We have already done once at the “nameservers” configuration in “/etc/netplan/50-cloud-init.yaml“. I wish I can explain it but not. This is what I do not like Ubuntu. It seems configuring “nameservers” in “50-cloud-init.yaml” is not enough to force the OS to use my preferred nameserver which is my DNS server in Synology. Let me know if you have any idea how to simplify this configuration.
Change the Ubuntu Hostname
It is in good practice to change the hostname to the configured domain name (DNS name) that we going to configure for each of the node. For example, change the node hostname to “node0.internal“. This change should be done at 2 places, which is the “/etc/hosts” and “/etc/hostname“.
Configure iptables for Bridge Traffics
Before we can proceed to configure the iptables. We need to ensure the “br_netfilter” and “overlay” modules are running.
You can verify the modules’ status with the following command
lsmod | grep br_netfilter
lsmod | grep overlayIf the “br_netfilter” and “overlay” are not running, please run the following command to load the modules.
sudo modprobe br_netfilter
sudo modprobe overlayNext, you can proceed to configure the iptables with the following details.
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
# Reload configs
sudo sysctl --systemDisable Ubuntu Swap
You need to disable the Ubuntu swap in order for the “kubelet” to run properly. You just need to run the following command to turn the swap off.
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
sudo swapoff -aLastly, once you have completed the above step, update the Ubuntu OS for one more time before proceeding.
You should just perform “apt update” but not “apt upgrade“. We do not want to have incident where kernel is being updated to newer version. Remember we are booting the Ubuntu over the network. Changes to kernel files and version is the last thing we want.
sudo apt update -yIf the kernel file or boot loaders are changed, we will need to go through the steps to restructure some of the boot loader files manually again as described in the Part 2 – PXE Boot Ubuntu.
At this point in time, it’s probably a good idea to duplicate a copy of the respective Ubuntu OS filesystems folder and the boot loader files in your storage server under “rpi-pxe” and “rpi-tftpboot” directories. You can use these as your golden copies for additional node deployments later.
I use the “cp -a” command to copy the folders to make sure all file permissions and attributes are maintained. I perform these “cp” commands directly at the storage server over the ssh command prompt session.
Installing Required Softwares
In this section, we are going to install the required container runtime for Kubernetes and then the “kubeadm”, “kubelet” and “kubectl” components.
Container Runtimes
We are running arm64 based Ubuntu OS on Raspberry Pi 4. Kubernetes supported container runtimes are containerd, CRI-O and Docker. Good news is there are arm64 based container images provided by these container runtimes.
Kubernetes is deprecating Docker runtime after v1.20, so we should not use Docker container runtime. It will still works if you try to install Docker as the container runtime.
I tried CRI-O but sadly there are many problems during installation. Although CRI-O claims to support and provide the arm64 container images but the installation always failed with messages complain that it could not find the arm64 container images.
You can look at some similar reports over the GitHub and internet. One of the similar situation is like this. I was facing problem to pull any of the required container images. This blocked me from proceeding further.
Finally, I settled with containerd. It works flawlessly with one exception, which is expected. We are running the Ubuntu OS on top of NFS storage and containerd will not run properly with NFS storage.
The containerd will fail to extract the container images onto the NFS filesystem. We need to configure an iSCSI storage for Ubuntu and format it to the supported filesystem to provide overlayfs. This iSCSI volume will be mounted for the specific directory containerd uses for container images storage — the root storage.
The following is the snipplet of the error messages if NFS storage is used for the containerd root storage.
### ----- kubeadm failed to pull images
ubuntu@kube1:~$ sudo kubeadm config images pull --v=5
I1118 02:47:52.624892 8813 initconfiguration.go:116] detected and using CRI socket: /run/containerd/containerd.sock
I1118 02:47:52.626228 8813 interface.go:431] Looking for default routes with IPv4 addresses
I1118 02:47:52.626272 8813 interface.go:436] Default route transits interface "eth0"
I1118 02:47:52.626653 8813 interface.go:208] Interface eth0 is up
I1118 02:47:52.626905 8813 interface.go:256] Interface "eth0" has 3 addresses :[192.168.0.221/24 2002:3c30:9aae:1:e65f:1ff:fe65:71a3/64 fe80::e65f:1ff:fe65:71a3/64].
I1118 02:47:52.626981 8813 interface.go:223] Checking addr 192.168.0.221/24.
I1118 02:47:52.627021 8813 interface.go:230] IP found 192.168.0.221
I1118 02:47:52.627059 8813 interface.go:262] Found valid IPv4 address 192.168.0.221 for interface "eth0".
I1118 02:47:52.627095 8813 interface.go:442] Found active IP 192.168.0.221
I1118 02:47:52.627195 8813 kubelet.go:203] the value of KubeletConfiguration.cgroupDriver is empty; setting it to "systemd"
I1118 02:47:52.652528 8813 version.go:186] fetching Kubernetes version from URL: https://dl.k8s.io/release/stable-1.txt
exit status 1
output: time="2021-11-18T02:48:46Z" level=fatal msg="pulling image: rpc error: code = Unknown desc = failed to pull and unpack image \"k8s.gcr.io/kube-apiserver:v1.22.4\": failed to extract layer sha256:56881f97d699ae0de395e3285cc54210bcc39aac903e019a5b55a85de0b0f111: failed to convert whiteout file \"usr/local/.wh..wh..opq\": operation not supported: unknown"
, error
### ----- manual image pull resulted in error
sudo ctr images pull k8s.gcr.io/kube-apiserver:v1.22.4
k8s.gcr.io/kube-apiserver:v1.22.4: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:c52183c0c9cd24f0349d36607c95c9d861df569c568877ddf5755e8e8364c110: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:13380cd5df803c413941a6e7116ed3c0c6dfa7f45fb444690b3e8a84ae7ec38f: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:fa5145ad538159cfd1f24a85d25e4f0ba3f4632e8da3b489e1378b71ee65071d: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:c48e4f4f069400e2c5df3ac1f83cda6f18c6155705477aefa9cc55942b457da4: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:dd8d757734eb43dc77c8f715644d1442dcb5b37feac7c97d80da18c309fe0bfe: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:8fdcfcac0b01d357204f208c76f0bcb09efb684f02c5cbe9b2875f211f818850: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 4.5 s total: 27.1 M (6.0 MiB/s)
unpacking linux/arm64/v8 sha256:c52183c0c9cd24f0349d36607c95c9d861df569c568877ddf5755e8e8364c110...
INFO[0011] apply failure, attempting cleanup error="failed to extract layer sha256:56881f97d699ae0de395e3285cc54210bcc39aac903e019a5b55a85de0b0f111: failed to convert whiteout file \"usr/local/.wh..wh..opq\": operation not supported: unknown" key="extract-309978447-S-oz sha256:459375f5a1bcbef7ea7f962bae07f69ca5cd38b32afcade50a260f540fc8042a"
ctr: failed to extract layer sha256:56881f97d699ae0de395e3285cc54210bcc39aac903e019a5b55a85de0b0f111: failed to convert whiteout file "usr/local/.wh..wh..opq": operation not supported: unknownInstall ContainerD
You can install containerd using the following commands. Just copy-paste onto the Ubuntu command prompt to proceed.
# Configure persistent loading of modules
sudo tee /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
# Load at runtime.
sudo modprobe overlay
sudo modprobe br_netfilter
# Ensure sysctl params are set
sudo tee /etc/sysctl.d/kubernetes.conf<<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
# Reload configs
sudo sysctl --system
# Install required packages
sudo apt install -y curl gnupg2 software-properties-common apt-transport-https ca-certificates
# Add Docker repo, make sure it is for arm64
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=arm64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# Install containerd
sudo apt update
sudo apt install -y containerd.io
# Create the config files. You need change to root in order to run the “containerd config” command
sudo su -
mkdir -p /etc/containerd
containerd config default>/etc/containerd/config.tomlConfigure iSCSI Drive for ContainerD Storage
You need to find out the location of the root directory for containerd storage from “/etc/containerd/config.toml“. Take note of this directory. It should looks similar to the following. We will need to mount the iSCSI volume for the root storage on “/var/lib/containerd“.
root = "/var/lib/containerd"
state = "/run/containerd"You need to stop the containerd process before proceed.
sudo systemctl stop containerdConnect to iSCSI
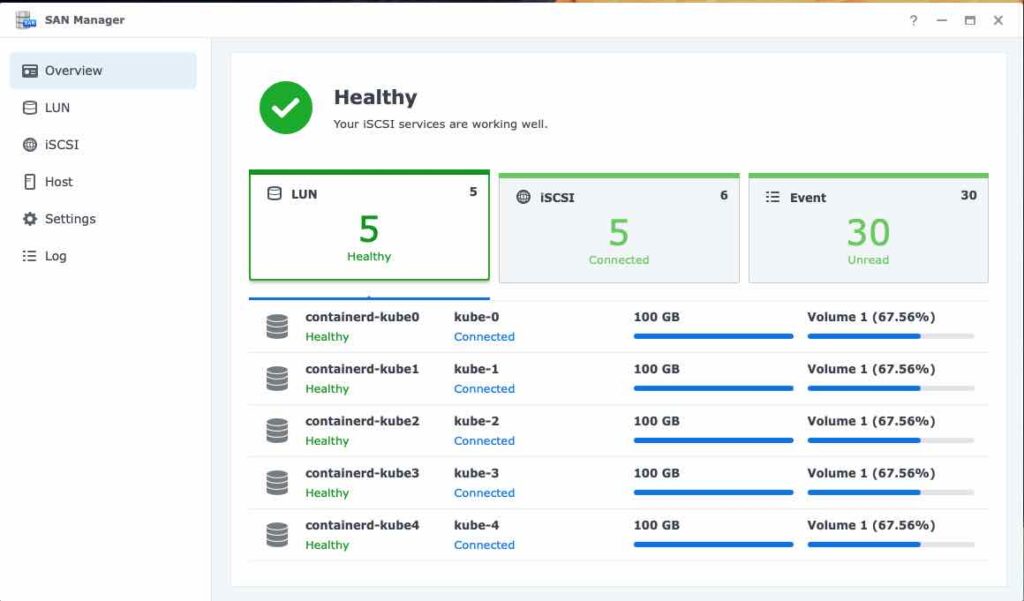
We need to create the necessary iSCSI storage at the storage server. In my case, I am using Synology. I have created the respective iSCSI and LUN entries in the SAN Manager as per the following screen shot.
Please proceed to create the necessary LUNs at your storage server if you have not done so.
Now, let’s proceed to install the iSCSI client.
sudo apt install open-iscsiWe proceed to configure the iSCSi client initiator in the “/etc/iscsi/initiatorname.conf“. The “InitiatorName” should be taken from your iSCSI server respective iSCSI Qualified Name (IQN).
# Edit
sudo nano /etc/iscsi/initiatorname.conf
# Add the following config
InitiatorName=iqn.2000-01.com.synology:synology-server.node0.6d23037b3e2Optionally, if authentication is enabled, you need to configure “/etc/iscsi/iscsid.conf” with the following authentication credential.
node.session.auth.authmethod = CHAP
node.session.auth.username = username
node.session.auth.password = passwordRestart the services after the configuration is done.
sudo systemctl restart iscsid open-iscsi Run the following command to discover the iSCSI targets
sudo iscsiadm -m discovery -t sendtargets -p <storage server ip address>You should be able to see the command output similar to the following which means the configuration is working fine.
10.0.0.2:3260,1 iqn.2000-01.com.synology:synology-server.default-target.6c12037c4e1
[2002:3c12:2c7b:1:211:32dd:dfa2:200d]:3260,1 iqn.2000-01.com.synology:synology-server.default-target.6c12037c4e1
[fe80::211:32dd:dfa2:200d]:3260,1 iqn.2000-01.com.synology:synology-server.default-target.6c12037c4e1
10.0.0.2:3260,1 iqn.2000-01.com.synology:synology-server.node0.6d23037b3e2
[2002:3c12:2c7b:1:211:32dd:dfa2:200d]:3260,1 iqn.2000-01.com.synology:synology-server.node0.6d23037b3e2
[fe80::211:32dd:dfa2:200d]:3260,1 iqn.2000-01.com.synology:synology-server.node0.6d23037b3e2Next, let’s connect to the iSCSI target volume
sudo iscsiadm --mode node --targetname iqn.2000-01.com.synology:synology-server.node0.6d23037b3e2 --portal <storage server ip> --loginThe expected result should be something similar to the following
Logging in to [iface: default, target: iqn.2000-01.com.synology:synology-server.node0.6d23037b3e2, portal: 10.0.0.2,3260] (multiple)
Login to [iface: default, target: iqn.2000-01.com.synology:synology-server.node0.6d23037b3e2, portal: 10.0.0.2,3260] successful.You should be able to see iSCSI volume is listed in Ubuntu OS now. You can verify this with the “fdisk” command.
sudo fdisk -lThe command should return the following output on top of other devices.
Disk /dev/sda: 200 GiB, 214748364800 bytes, 419430400 sectors
Disk model: Storage
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytesCreating the Logical Volume
At this point, we can proceed to create the newly attached iSCSI volume as logical volume
# Create the logical volume
sudo fdisk /dev/sda
# Choose n to create new partition
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
# Partition number and size
Select (default p): p
Partition number (1-4, default 1): 1
First sector (2048-419430399, default 2048):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-419430399, default 419430399):
Created a new partition 1 of type 'Linux' and of size 200 GiB.
# Write to partition table and exit
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Next, let’s create the volume group. In here, I named mine as “vgcontainerd“. You can name whatever that is relevant to you.
sudo vgcreate vgcontainerd /dev/sda1You should receive the following similar command output as a result.
Physical volume "/dev/sda1" successfully created.
Volume group "vg-crio" successfully createdNext, let’s proceed to create the logical volume. You can choose the logical volume whichever relevant to you.
sudo lvcreate -l 100%FREE -n lvcontainerd vgcontainerdThe following is the expected similar command output.
ubuntu@node0:~$ sudo lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lvcontainerd vgcontainerd -wi-a----- <200.00g Next, let’s proceed to format the logical volume with XFS filesystem format. This will provide the overlayfs filesystems that is required by containerd root storage.
# Find out the mapper name
ls /dev/mapper
# Format
sudo mkfs.xfs /dev/mapper/vgcontainerd-lvcontainerdThe expected output from the above command.
meta-data=/dev/mapper/vgcontainerd-lvcontarinerd isize=512 agcount=4, agsize=13106944 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=52427776, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=25599, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Now, let’s mount the logical volume on ‘/etc/lib/containerd‘ permanently. We can do this by configuring the “/etc/fstab” file with the following entry. Please change the respective paths accordingly before save the changes.
# Edit the fstab and add the following entry
/dev/mapper/vgcontainerd-lvcontainerd /var/lib/containerd xfs _netdev 0 0
# Mount the volume
sudo mount -aYou can run the following command to double check the result
sudo df -hT | grep /var/lib/containerd
### Expected result
/dev/mapper/vgcontainerd-lvcontarinerd xfs 200G 1.5G 199G 1% /var/lib/containerdWe want to make sure that iSCSI client and services are auto-started whenever the Raspberry Pi is rebooted. We need to configure the following to achieve that.
sudo iscsiadm -m node --op=update -n node.conn[0].startup -v automatic
sudo iscsiadm -m node --op=update -n node.startup -v automaticAdditionally, you also need to change the “/etc/iscsi/iscsid.conf” with the following modification
# Edit
sudo nano /etc/iscsi/iscsid.conf
# Change the following
node.startup = automatic
#node.startup = manualLastly, please execute the following commands to make sure that the iSCSI services are available during OS initialization.
sudo systemctl enable open-iscsi
sudo systemctl enable iscsidNote: I am trying to find out how to configure a specific RPI node to only connect to one iSCSI target (the designated target for that specific RPI node). The current situation is a RPI node will connect to multiple iSCSI targets at once and this is causing other RPI nodes which booted later failed to connect to it’s own iSCSI target. Please let me know if you have any idea how to configure this.
Make Sure ContainerD Service Starts after iSCSI is Mounted During Boot Time
Let’s find out the iSCSI mount unit using the following command
systemctl list-units --type=mount The command output should be similar to the following. Please take note of the unit name for the mount point which is “var-lib-containerd.mount” for “/var/lib/containerd” in this example.
UNIT LOAD ACTIVE SUB DESCRIPTION
tmp.mount loaded active mounted /tmp
var-lib-containerd.mount loaded active mounted /var/lib/containerd Let’s modify the containerd service configuration at “/etc/systemd/system/containerd.service“. You should append the storage unit name from the above right after the “After” stanza. This will make sure the containerd service is only being started after the iSCSI storage is mounted and available.
[Unit]
Description=Container Runtime Interface for OCI (CRI-O)
Documentation=https://github.com/cri-o/cri-o
Wants=network-online.target
Before=kubelet.service
After=network.target local-fs.target var-lib-containerd.mountAfter making the changes, we need to reload the daemon and restart the containerd. You should try to reboot the system and observe whether all the configurations work as expected.
sudo systemctl daemon-reload
sudo systemctl start containerd
# check the status that the containerd is running and active without problem
sudo systemctl status containerdInstalling kubeadm, kubelet and kubectl
Let’s do a update on the Ubuntu OS before proceed. We need to install some packages before proceed.
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curlNext, let’s install the Google Cloud public key
sudo curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpgWe also need to add the Kubernetes apt repository.
echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.listFinally, let’s proceed to update the apt package index followed by the installation of the kubeadm, kubelet and kubectl
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectlIt is best to specify the version to install using the following parameter at the command. This is to ensure that we are installing consistent version for all the Kubernetes nodes.
sudo apt-get install -qy kubelet=1.22.4-00 kubectl=1.22.4-00 kubeadm=1.22.4-00We also want to make sure the “kube*” components are not accidentally updated when you run “apt update” command in the future. You should run the following command to lock down the “kube*” components.
sudo apt-mark hold kubelet kubeadm kubectlNote: You may be facing some files permission issues as per the following. You can either run “chmod -R +rx” on the directories or perform a system reboot to overcome the problem. I suspect this could be the site effect of PXE boot with NFS storage. Let me know if you have any idea of why this is happening.
Unpacking kubernetes-cni (0.8.7-00) ...
dpkg: error processing archive /tmp/apt-dpkg-install-g85XU1/4-socat_1.7.3.3-2_arm64.deb (--unpack):
cannot access archive '/tmp/apt-dpkg-install-g85XU1/4-socat_1.7.3.3-2_arm64.deb': Permission denied
No apport report written because the error message indicates an issue on the local system
dpkg: error processing archive /tmp/apt-dpkg-install-g85XU1/5-kubelet_1.22.3-00_arm64.deb (--unpack):
cannot access archive '/tmp/apt-dpkg-install-g85XU1/5-kubelet_1.22.3-00_arm64.deb': Permission denied
No apport report written because the error message indicates an issue on the local system
dpkg: error processing archive /tmp/apt-dpkg-install-g85XU1/6-kubectl_1.22.3-00_arm64.deb (--unpack):
cannot access archive '/tmp/apt-dpkg-install-g85XU1/6-kubectl_1.22.3-00_arm64.deb': Permission denied
No apport report written because the error message indicates an issue on the local system
dpkg: error processing archive /tmp/apt-dpkg-install-g85XU1/7-kubeadm_1.22.3-00_arm64.deb (--unpack):
cannot access archive '/tmp/apt-dpkg-install-g85XU1/7-kubeadm_1.22.3-00_arm64.deb': Permission denied
No apport report written because MaxReports is reached already
Errors were encountered while processing:Creating the Kubernetes Cluster
If everything goes perfectly fine till this point, you are ready to create your Kubernetes cluster on RPI4 with Ubuntu.
You can run the “kubeadm init” command directly to initiate the cluster. The necessary container images will be pulled during the command execution.
I prefer to pull the necessary container images before initializing the cluster. In this approach I will be able to make sure that the container images can be pulled without problem before proceeding.
Another reason is pulling container images will take some time. I will just let it runs, grabs a coffee and comes back to it later.
Run the following command to pull all the necessary container images
sudo kubeadm config images pullNext, you can execute the “kubeadm init” command to initialize the Kubernetes cluster. Note that the “—control-plane-endpoint” is “lb.kube.internal” which is resolved to the HAProxy nodes at the virtual IP address.
The HAProxy is then load balance the requests to backends at the control plane server which is “10.0.0.110” in this example. The “—apiserver-advertise-address” is pointing to the respective control plane IP address.
sudo kubeadm init \
--control-plane-endpoint=lb.kube.internal \
--apiserver-advertise-address=10.0.0.110 \
--kubernetes-version=1.22.4 \
--pod-network-cidr=10.244.0.0/16Note: Please make sure the port 6443 which is used by the control plane API server is exposed and accessible at the HAProxy and the control plane node before proceed to initialize the cluster. You can use command “nc -zv <ip> 6443” to verify the port is opened and you can connect to it.
If everything works fine, you should be able to see the following command output
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join lb.kube.internal:6443 --token 8eojyy.c41ns65r4nujqtrc \
--discovery-token-ca-cert-hash sha256:0d4ebac42c2903e5fbc03704c092add558f493b9fbe5569b9aa44045a38251dc \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join lb.kube.internal:6443 --token 8eojyy.c41ns65r4nujqtrc \
--discovery-token-ca-cert-hash sha256:0d4ebac42c2903e5fbc03704c092add558f493b9fbe5569b9aa44045a38251dc At this point in time, you will get “not ready” status when query the cluster using “kubectl get nodes” command. You will also see lots of “cni plugin error” in “journalctl” output. To resolve this, you need to install the Pod Network add-on at the next section.
Installing Pod Network Add-on
You must deploy a Container Network Interface (CNI) based Pod network add-on to allow the Pods to be able to communicate with each others. Cluster DNS (CoreDNS) will not start up before a network is installed.
There are a number of CNI network add-on that supports Kubernetes. I chose to install Flannel add-on because it is one of the easiest to install. Kubernetes documentation claims that many people have reported success with Flannel and Kubernetes.
Run the following command to install Flannel
sudo kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.ymlIf all goes well, you should be able to see the cluster with the “node ready” status. You can now proceed to add more control planes and worker nodes into the cluster.
Preparing Additional Nodes
If you have made golden copies of the Ubuntu boot loader files and the OS filesystems, you can duplicate the golden copies and named the duplicated directories with the proper names at the storage server. You also need to make sure the “cmdline.txt” and network configurations are changed accordingly. Refers the earlier sections in this post for more detail. You can do this by modifying the respective files at the storage server before booting the RPI node.
From there onward, you can just repeat the same procedures outlined in the Install Required Software section.
The golden copies approach save you a lot of time and now you can proceed to add these nodes as control planes or worker nodes.
Joining The Control Plane
Once the RPI node booted with all properly configured. You can proceed to add the node as control plane.
You can just copied the command output from “kubeadm init” earlier to join a node as control plane. Run this command at the node that you want to join from. The issue with using this command requires you to manually copy the CA certs and token to the node that you wish to join from. If you feel like adventurous, please refer the documentation to proceed, otherwise please refer to the next.
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join lb.kube.internal:6443 --token 8eojyy.c41ns65r4nujqtrc \
--discovery-token-ca-cert-hash sha256:0d4ebac42c2903e5fbc03704c092add558f493b9fbe5569b9aa44045a38251dc \
--control-plane To save the hassle of copying CA certs and token, you can just run the following command to create a new certificates and join the node using the generated command in the output.
# new token
sudo kubeadm init phase upload-certs --upload-certs
# Replace the <key> from the output of the first command.
# This will print the complete join command that you can just and paste to join new control plane.
sudo kubeadm token create --certificate-key <key> --print-join-command
# Join the control-plane node. Generated from the second command above.
sudo kubeadm join lb.kube.internal:6443 --token gsz2hy.77rj58mkhu06ovim --discovery-token-ca-cert-hash sha256:0d4ebac42c2903e5fbc03704c092add558f493b9fbe5569b9aa44045a38251dc --control-plane --certificate-key 1c93da0c8bb98083c39c5323bb9b5a4db581546cb3b5da059d909b516cb08610The token will expires after 24 hours. If you are joining nodes 24 hours after the “kubeadm init” command is issued, you will need to recreate the certificates and token. This is where you will find the second set of the commands above are handy for these situations.
Joining The Worker Node
To join worker node is pretty straightforward.
Assuming the RPI node is prepared with the pre-requisitions. You can run the following command to join worker nodes. This time run the command without the “--control-plane” parameter. Remember to replace the following example with the correct certificate values and token.
kubeadm join lb.kube.internal:6443 --token gsz2hy.77rj58mkhu06ovim --discovery-token-ca-cert-hash sha256:0d4ebac42c2903e5fbc03704c092add558f493b9fbe5569b9aa44045a38251dc --certificate-key 1c93da0c8bb98083c39c5323bb9b5a4db581546cb3b5da059d909b516cb08610The following is the expected command output
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: hugetlb
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.Finally, you have your Kubernetes cluster running on Raspbery Pi 4 and ready for more adventures.
Summary
Installing Kubernetes is a long and complicated process. Proper planning and design are essential for a successful deployment. The information for K8s deployment is out there but some time they are not pieced together clearly, partly also because there are too many options available.
This is like connecting dots in your brain. Once you have these dots connected, things become clear and easy. It’s like Eureka! I hope this post helps to connect the dots and you can advance further from here.
There are many other configurations are required to get the cluster “production” ready. I will be covering more of these in the next posts. Please stay tuned!