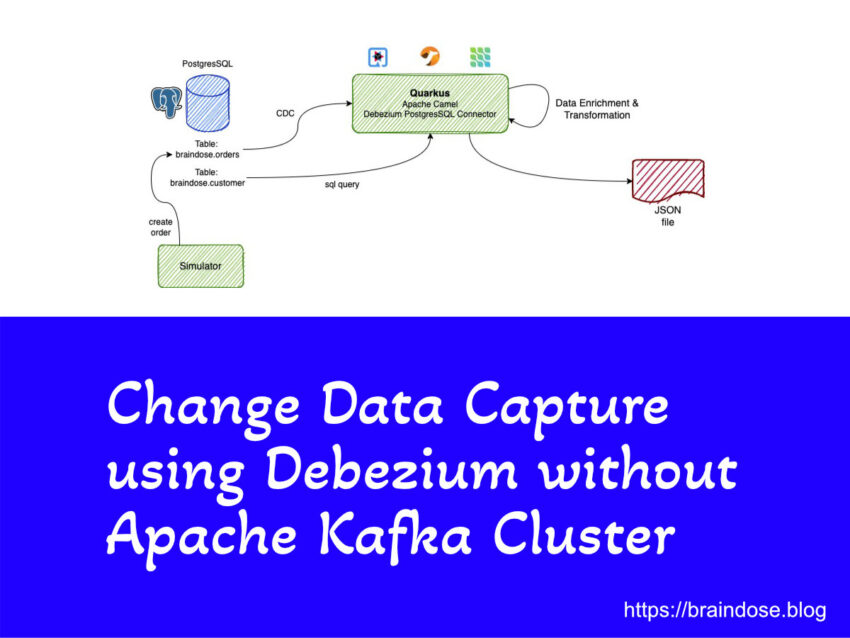
Debezium is developed base on Kafka Connect framework and we need Apache Kafka cluster to store the captured events data from source databases. Sometime we do not require the level of tolerance and reliability provided by Apache Kafka cluster, but you still need Change Data Capture (CDC). This is where Debezium Engine come into the picture.