
Table of Contents
- Overview of Apache Kafka Connect
- Apache Kafka Connect on OpenShift
- Creating MongoDB Kafka Connect Container Image
- Summary
Overview of Apache Kafka Connect
In Apache Kafka architecture, Kafka Connect is an integration toolkit for streaming data between Kafka brokers and other systems using Connector plugins. Kafka Connect provides a framework for integrating Kafka with an external data source or target, such as a database, for import or export of data using connectors.
Connectors are plugins that provide the connection configuration needed. There are 2 type of connectors:
- A source connector pushes external data into Kafka
- A sink connector extracts data out of Kafka
Apache Kafka Connect on OpenShift
Red Hat commercial version of Apache Kafka is Red Hat AMQ Streams (AMQ Streams for OpenShift is based on Strimzi). The same architecture of Apache Kafka Connect is provided out of box in Red Hat AMQ Streams.
There are 2 part of procedure in order to deploy Kafka Connect to OpenShift.
- Firstly, you need to decide which type of connector is required and create the necessary container image with the connector for your Kafka Connect.
- Secondly, you need to configure Kafka Connect with the required bootstrap and topic information. You can refer to the Kafka Connect configuration information here.
Creating MongoDB Kafka Connect Container Image
There are 2 ways to create the Kafka Connect container image
- A Kafka container image on Red Hat Container Catalog as a base image
- OpenShift builds and the Source-to-Image (S2I) framework to create new container images
In this tutorial, I am going to focus on how to create a MongoDB source connector using the first approach by building the container image using the Red Hat base image.
Please note that this is part of the extension details of the earlier article that I had published — Implement Event Based Microservices Application with Apache Kafka on OpenShift.
I will refer to this Payment Gateway for all future articles. The complete deployable asset for this tutorial can be accessed from here.
Create a directory on your local system. For this example we named the directory as MongoDBConnector. Create another directory named mongo-plugin.
Download the MongoDB connector library from the MongoDB website. Extract the downloaded file and you will have the following file contents. Copy the mongo-kaka-1.1.0-all.jar into the mongo-plugin directory.
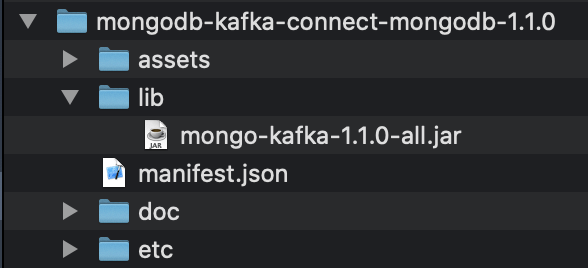
Create a Dockerfile with the following content in the MongoDBConnector directory.
FROM registry.redhat.io/amq7/amq-streams-kafka-24-rhel7
USER root:root
COPY ./mongo-plugins/ /opt/kafka/plugins/
USER kafka:kafkaYou may find the detail of this specific base image from Red Hat Container Catalog at this location. Please refer to this page for how to get the base image. You need to have a valid account to authenticate to the Red Hat container registry.
The following shows the completed MongoDBConnector directory content.
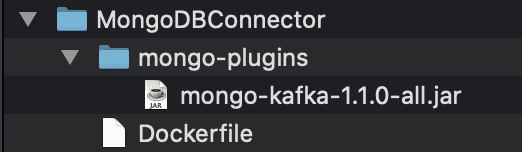
In the same MongoDBConnector directory, run the following command to build the container image using Docker engine.
docker build --tag amq-streams-kafka-connect-24:latest .The following is the output of the docker build
Sending build context to Docker daemon 4.238MB
Step 1/4 : FROM registry.redhat.io/amq7/amq-streams-kafka-24-rhel7
---> 166f74d8a6af
Step 2/4 : USER root:root
---> Running in 8cded2889470
Removing intermediate container 8cded2889470
---> aaa8079ea901
Step 3/4 : COPY ./mongo-plugins/ /opt/kafka/plugins/
---> 25c094e19fed
Step 4/4 : USER kafka:kafka
---> Running in 5c9b7076b604
Removing intermediate container 5c9b7076b604
---> 987f65ecc3fa
Successfully built 987f65ecc3fa
Successfully tagged amq-streams-kafka-connect-24:latestSummary
Creating your own version of container image for Kafka Connect for OpenShift is pretty straightforward with simple few steps. The only hassle is to look for the right connector plugin for your use case, which you basically just need to head to the respective product vendor website to look for it.