Table of Contents
Overview
Debezium is developed base on Kafka Connect framework and we need Apache Kafka cluster to store the captured events data from source databases. Kafka Connect provides excellent fault tolerance and scalability by making sure there is always connectors running in distributed mode, in the cluster. Sometime database use case does not require this level of tolerance and reliability, or maybe it is not justifiable to implement an Apache Kafka Cluster just to capture a small set of tables data, but you still need Change Data Capture (CDC). This is where Debezium Engine come into the picture.
What is Debezium Engine?
Debezium engine is Java API modules that you can embedded into your application so that the database changes can be captured using the same approach by monitoring the committed database redo log. Debezium Engine API module allows your application to perform CDC and data processing before the event data is sent to the downstream consumers such as messaging platform, databases, or other applications, using your choices of protocols and data formats.
In order to use the Debezium Engine, you will need to add the required dependencies. The detail of how to implement using Debezium Engine API is not the focus of this post but we will look at how to perform CDC using the Apache Camel.
For details on Debezium Engine, please refer to the Debezium Engine product documentation.
To implement using Debezium Engine API, you need to write your own codes and logic. For CDC and data processing use cases, we often requires to enrich the existing database event data. Data enriching can be done by retrieving the data from the same database or integrating to other systems (or databases). The integration implementation can be challenging and requires a lot of effort. This can be simplified by using the Debezium Connector Extensions provided by Apache Camel.
What is Apache Camel?
Apache Camel is an open source framework for message-oriented middleware with features such as rule-based routing, mediation and transformation. It supports wide rage of integration protocols and data formats, and provides integration best practices via the industry proven Enterprise Integration Patterns.
In most cases, nowadays, we want to be able to implement the solution for container, microservices and serverless. This is where we can implement Apache Camel using the Apache Camel extensions for Quarkus.
In other words, you can use Quarkus framework to implement the CDC using the Debezium Connector Extensions and at the same time being able to integrate to 3rd party systems using the Apache Camel Extension for Quarkus.
All-in-one meal package!
What is Quarkus?
Quarkus is a Java framework tailored for deployment on Kubernetes. Key technology components surrounding it are OpenJDK HotSpot and GraalVM. The goal of Quarkus is to make Java a leading platform in Kubernetes and serverless environments while offering developers a unified reactive and imperative programming model to optimally address a wider range of distributed application architectures.
It is statically proven that Quarkus can perform better compared to other Java frameworks and thus it is not only suitable for microservices but also serverless implementation. You can find out more about Quarkus performance information on this blog.
Implementing Debezium Engine in Quarkus
Overview
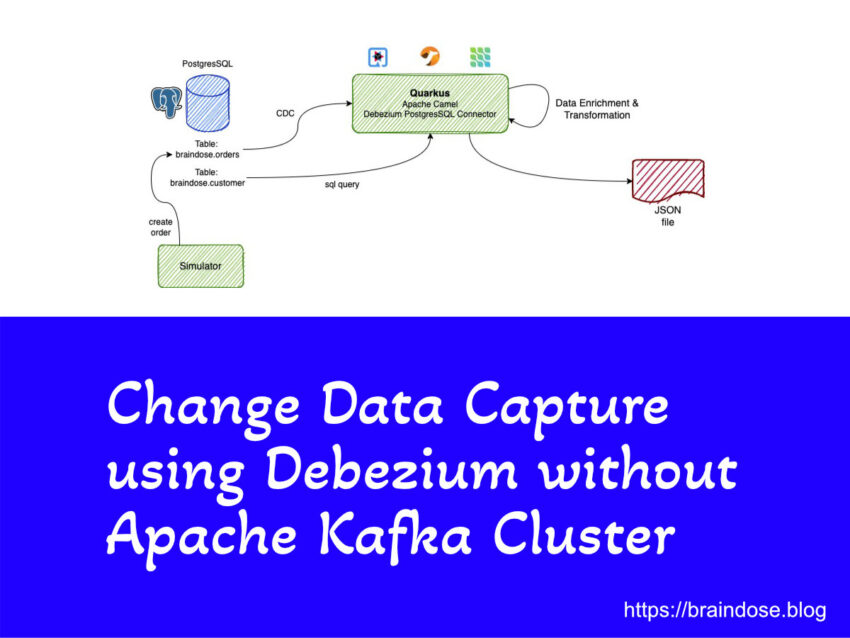
The scenarios in this post is looking at how can we capture database changes from a specific table in PostgresSQL database and perform a simple data enrichment before this enriched data is converted into JSON format and stored in a plain text file.
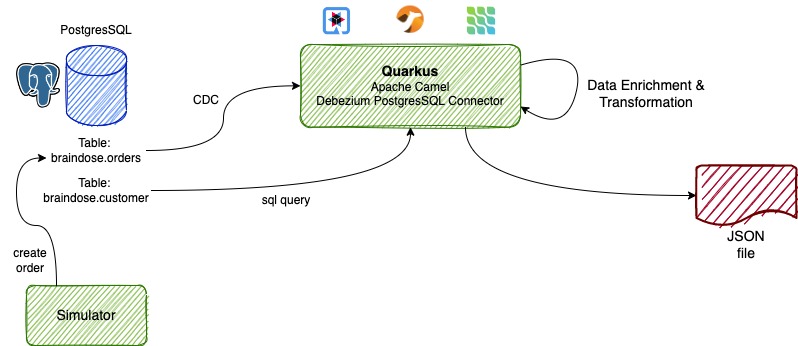
The Quarkus application is implemented using the Debezium PostgresSQL Connector and it is capturing the new records created in the braindose.orders table. New orders are created by the Simulator apps. Each new order will create a new entry in the braindose.orders and braindose.customerorders tables. In this case, we only interested for the data in the orders table.
The event data is further enriched with customer name and custid in the Camel integration flow. This is done by performing a SQL query to the braindose.customer and braindose.customerorder tables, using the Apache Camel SQL Extension.
In real life scenario, the integrations and data enrichments can be coming from external 3rd party systems that can be located in the same data centre or at remote locations.
Note: This is a simplified demo showcase. Many details implementations such as circuit breaker and exception handling are omitted for simplication.
Now, let’s look at the details at the next sections.
Implementing Camel Quarkus Project
Bootstrap the Quarkus Project
You can quickly bootstrap a Quarkus project at code.quarkus.com to include all the dependencies required.
You can also bootstrap the Quarkus project using quarkus or mvn command line interfaces.
You need to include the following dependencies.
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-language</artifactId>
</dependency>
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-bean</artifactId>
</dependency>
<!- Dependency for Debezium PostgresSQL Connector ->
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-debezium-postgres</artifactId>
</dependency>
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-direct</artifactId>
</dependency>
<!- Dependency for using SQL extension to connect to database ->
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-sql</artifactId>
</dependency>
<!- Dependency for creating and reading files ->
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-file</artifactId>
</dependency>
<!- Dependency for JSON ->
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-jackson</artifactId>
</dependency>Defining the Debezium PostgresSQL Connector Settings
You need to create a Java class to get started. This Java class need to extend the org.apache.camel.builder.RouteBuilder class. You can refer the Routes.java at the GitHub for the complete sample codes used in this post.
package blog.braindose.demo.dbz.camel;
import org.apache.camel.Message;
import org.apache.camel.builder.RouteBuilder;
import org.apache.kafka.connect.data.Struct;
import blog.braindose.demo.dbz.camel.model.CustomerOrder;
import java.util.List;
import java.util.Map;
public class Routes extends RouteBuilder {
// ...
// Omitted codes
// ...
@Override
public void configure() throws Exception {
// ...
// Omitted codes
// ...
}
}Next, we need to define the settings for Debezium PostgresSQL connector. For this case, we are going to configure the values via the environmental variables. For example, dbz.offset.file is configured via DBZ_OFFSET_FILE environmental variable.
This approach allow us to dynamically define the values when we run this project as container later. We will look into this later when we configure the Docker compose file.
For a complete list of configurations, please refer to the Connector documentation at Apache Camel website.
String DBZ_SETTINGS = "debezium-postgres:dbz-camel?offsetStorageFileName={{dbz.offset.file}}" +
"&databaseDbname={{db.name}}" +
"&databaseHostname={{db.host}}" +
"&databasePort={{db.port}}" +
"&databaseUser={{db.user}}" +
"&databasePassword={{db.password}}" +
"&databaseServerName={{dbz.dbservername}}" +
"&databaseHistoryFileFilename={{dbz.dbhistoryfile}}" +
"&schemaIncludeList={{dbz.schemaincludelist}}" +
"&tableIncludeList={{dbz.tableincludelist}}";Next, we are going to implement the Camel logic to read committed transactions from PostgresSQL database redo log.
First thing we need to do is to configure the Debezium PostgresSQL connector using the DBZ_SETTINGS variable from the above code.
In the above example, we also define which database schema and table to include in the CDC via the schemaIncludeList and tableIncludeList configuration.
from(DBZ_SETTINGS)Next, the CDC result is populated into the CustomerOrder POJO object
.process(
exchange -> {
// Create a CustomerOrder POJO
Message in = exchange.getIn();
final Struct body = in.getBody(Struct.class);
CustomerOrder order = new CustomerOrder(
body.getString("orderid"),
body.getString("orderdate"),
body.getString("sku"),
body.getString("description"),
body.getFloat64("amount"));
in.setBody(order);
})Enriching Data with Database Connection
With the even data from the orders table, we are using the the orderId to query the same database to retrieve the customer name and custid. This is done via the SQL Camel extension. The SQL query detail can be found from the customer.sql file located in the project’s resource directory.
The SQL query result is then updated into the existing CustomerOrder object.
.setProperty("orderDetail", simple("${body}"))
.setProperty("orderId", simple("${body.orderId}"))
// Connect to the database to query the customer name and custid using the orderid
.to("sql:classpath:sql/customer.sql")
.log("SQL Query from customer table: ${body}")
.process(
exchange -> {
CustomerOrder order = (CustomerOrder) exchange.getProperty("orderDetail");
Message in = exchange.getIn();
String custname = (String) ((Map) ((List) in.getBody()).get(0)).get("name");
Integer custId = (Integer) ((Map) ((List) in.getBody()).get(0)).get("custId");
order.setCustName(custname);
order.setCustId(custId);
in.setBody(order);
})In order to connect to the PostgresSQL database, we need to configure the Data Source in the Quarkus project.
This is done via the application.properties configuration as per the following. You can refer to Quarkus Application Configuration guide for more detail for how to utilize the application configurations feature provided by Quarkus framework.
We are configuring these settings using environmental variables. We will look at this when we configure the Docker compose file in the later section.
quarkus.datasource.db-kind=postgresql
quarkus.datasource.username=${DB_USER}
quarkus.datasource.password=${DB_PASSWORD}
quarkus.datasource.jdbc.url=jdbc:postgresql://${DB_HOST}:${DB_PORT}/${DB_NAME}
quarkus.datasource.jdbc.max-size=16
quarkus.native.resources.includes = sql/*.sqlNote: The Apache Camel integrations are provided by extensions and components. There are around 306 extensions and 288 components available today in Camel Extension for Quarkus.
Converting Java Object to JSON
At the end of the implementation, the CustomerOrder object is converted into JSON and appended into the preconfigured plaintext file.
// convert the customerOrder Java object into JSON formatted string
.marshal().json()
.log("Transform Order Object to Json: ${body}")
// append to the external file
.to("file:{{output.dir}}?fileName={{output.filename}}&appendChars=\n&fileExist=Append")
.log("JSON data saved into file.")Note: Other than JSON format, there are around 43 data formats supported by Apache Camel extension for Quarkus.
Complete Camel Codes
The following shows the complete Camel implementation.
// Capture database event from PostgresSQL database
from(DBZ_SETTINGS)
.log("Event received from Debezium : ${body}")
.process(
exchange -> {
// Create a CustomerOrder POJO
Message in = exchange.getIn();
final Struct body = in.getBody(Struct.class);
CustomerOrder order = new CustomerOrder(
body.getString("orderid"),
body.getString("orderdate"),
body.getString("sku"),
body.getString("description"),
body.getFloat64("amount"));
in.setBody(order);
})
.log("Captured order: ${body}")
.setProperty("orderDetail", simple("${body}"))
.setProperty("orderId", simple("${body.orderId}"))
// Connect to the database to query the customer name and custid using the orderid
.to("sql:classpath:sql/customer.sql")
.log("SQL Query from customer table: ${body}")
.process(
exchange -> {
CustomerOrder order = (CustomerOrder) exchange.getProperty("orderDetail");
Message in = exchange.getIn();
String custname = (String) ((Map) ((List) in.getBody()).get(0)).get("name");
Integer custId = (Integer) ((Map) ((List) in.getBody()).get(0)).get("custId");
order.setCustName(custname);
order.setCustId(custId);
in.setBody(order);
})
.log("Enriched Order: ${body}")
// convert the customerOrder Java object into JSON formatted string
.marshal().json()
.log("Transform Order Object to Json: ${body}")
// append to the external file
.to("file:{{output.dir}}?fileName={{output.filename}}&appendChars=\n&fileExist=Append")
.log("JSON data saved into file.")
;Running the Samples
You can run the demo by using the Docker compose file provided in the GitHub project. Clone the GitHub project onto your local disk and run the following command in the camel-dbz project folder.
You will need to have JDK and Apache Maven installed in your local machine in order to build the project before packaging them to run as container. The build process will take a while if this is the first time you perform the build.
$ docker compose up --buildIn the Docker compose file, please note that the following environmental variables are configured for the camel service which are used to configure the Debezium PostgresSQL connector in the earlier section.
environment:
- DB_NAME=dbzdemo
- DBZ_OFFSET_FILE=/deployments/data/offset-file-1.dat
- DB_HOST=postgres
- DB_PORT=5432
- DB_USER=camel
- DB_PASSWORD=camel
- DBZ_DBSERVERNAME=camel-dbz-connector
- DBZ_DBHISTORYFILE=/deployments/data/history-file-1.dat
- DBZ_SCHEMAINCLUDELIST=braindose
- DBZ_TABLEINCLUDELIST=braindose.orders
- OUTPUT_DIR=/tmp/dbzdemo
- OUTPUT_FILENAME=dbz-camel-order.outputThe Simulator application is written in Quarkus framework and is using cron job to randomly create new orders in the braindose.orders table.
camel-dbz-simulator-1 | 2022-12-08 06:20:00,008 INFO [blo.bra.dem.deb.cam.sim.DBSimulator] (executor-thread-0) Simulating new order now ...
camel-dbz-simulator-1 | 2022-12-08 06:20:00,011 INFO [blo.bra.dem.deb.cam.sim.DBSimulator] (executor-thread-0) The lucky customer is: Customer [custId=14, name=Anderson Hilton]
camel-dbz-simulator-1 | 2022-12-08 06:20:00,011 INFO [blo.bra.dem.deb.cam.sim.DBSimulator] (executor-thread-0) The lucky SKU is: Sku [sku = MW11287, decription=iPad 9th Generation,price = 329.0]You will observe the following output at the command prompt when the Camel service is processing the CDC event data.
camel-dbz-camel-1 | 2022-12-08 06:16:18,922 INFO [route1] (Camel (camel-1) thread #1 - DebeziumConsumer) Event received from Debezium : Struct{orderid=B-20221208-061618027-81537,orderdate=2022-12-08T06:16:18.027Z,sku=MW84287,description=Green Alpine Loop,amount=99.0}
camel-dbz-camel-1 | 2022-12-08 06:16:18,925 INFO [route2] (Camel (camel-1) thread #1 - DebeziumConsumer) Captured order: Order [orderId=B-20221208-061618027-81537, custId=0, custName=null, orderdate=Thu Dec 08 06:16:27 GMT 2022, sku=MW84287]
camel-dbz-camel-1 | 2022-12-08 06:16:18,969 INFO [route2] (Camel (camel-1) thread #1 - DebeziumConsumer) SQL Query from customer table: [{custid=29, name=Alfred Hugo}]
camel-dbz-camel-1 | 2022-12-08 06:16:18,969 INFO [route2] (Camel (camel-1) thread #1 - DebeziumConsumer) Enriched Order: Order [orderId=B-20221208-061618027-81537, custId=29, custName=Alfred Hugo, orderdate=Thu Dec 08 06:16:27 GMT 2022, sku=MW84287]
camel-dbz-camel-1 | 2022-12-08 06:16:18,971 INFO [route2] (Camel (camel-1) thread #1 - DebeziumConsumer) Transform Order Object to Json: {"custId":29,"orderId":"B-20221208-061618027-81537","custName":"Alfred Hugo","orderdate":1670480187000,"sku":"MW84287","description":"Green Alpine Loop","amount":99.0}
camel-dbz-camel-1 | 2022-12-08 06:16:18,983 INFO [route2] (Camel (camel-1) thread #1 - DebeziumConsumer) JSON data saved into file.The results are appended at the the output file configured at environmental variables OUTPUT_DIR and OUTPUT_FILENAME in the Docker compose file.
$ tail -f /tmp/dbzdemo/dbz-camel-order.output
{"custId":20,"orderId":"B-20221208-061553010-96134","custName":"Clinton Hill","orderdate":1670480101000,"sku":"MW2729","description":"Sunglow Solo Loop","amount":49.0}
{"custId":22,"orderId":"B-20221208-061558020-46718","custName":"Sky High","orderdate":1670480121000,"sku":"MW11284","description":"iPad 10th Generation","amount":499.0}
{"custId":14,"orderId":"B-20221208-061603026-75192","custName":"Anderson Hilton","orderdate":1670480186000,"sku":"MW11118","description":"Apple Macbook Pro 16\"","amount":249Summary
In this post we have gone through quickly how to use the Debezium CDC in Apache Camel for Quarkus. The Debezium Connectors extension provided by Apache Camel is implemented based on the Debezium Engine framework. This provides CDC feature on top of many other capabilities offered by Apache Camel.
Last but not least, Red Hat provides the complete commercially support solution via the Red Hat Integration portfolio. Correction, the Camel Debezium Connector is community supported today. It is my mistake to assume it is supported by Red Hat. Refer code.quarkus.redhat.com for the supportability. Components supported by Red Hat will be indicated with “SUPPORTED” label.